The core idea behind Amazon Redshift:
- Amazon Redshift is a fully managed, scalable cloud data warehouse from Amazon Web Services.
- It is designed for analytics on large-scale (TB–PB) data, not for transactional workloads.
OLTP vs OLAP (Key Concept)
1. OLTP Systems (e.g., Amazon RDS)
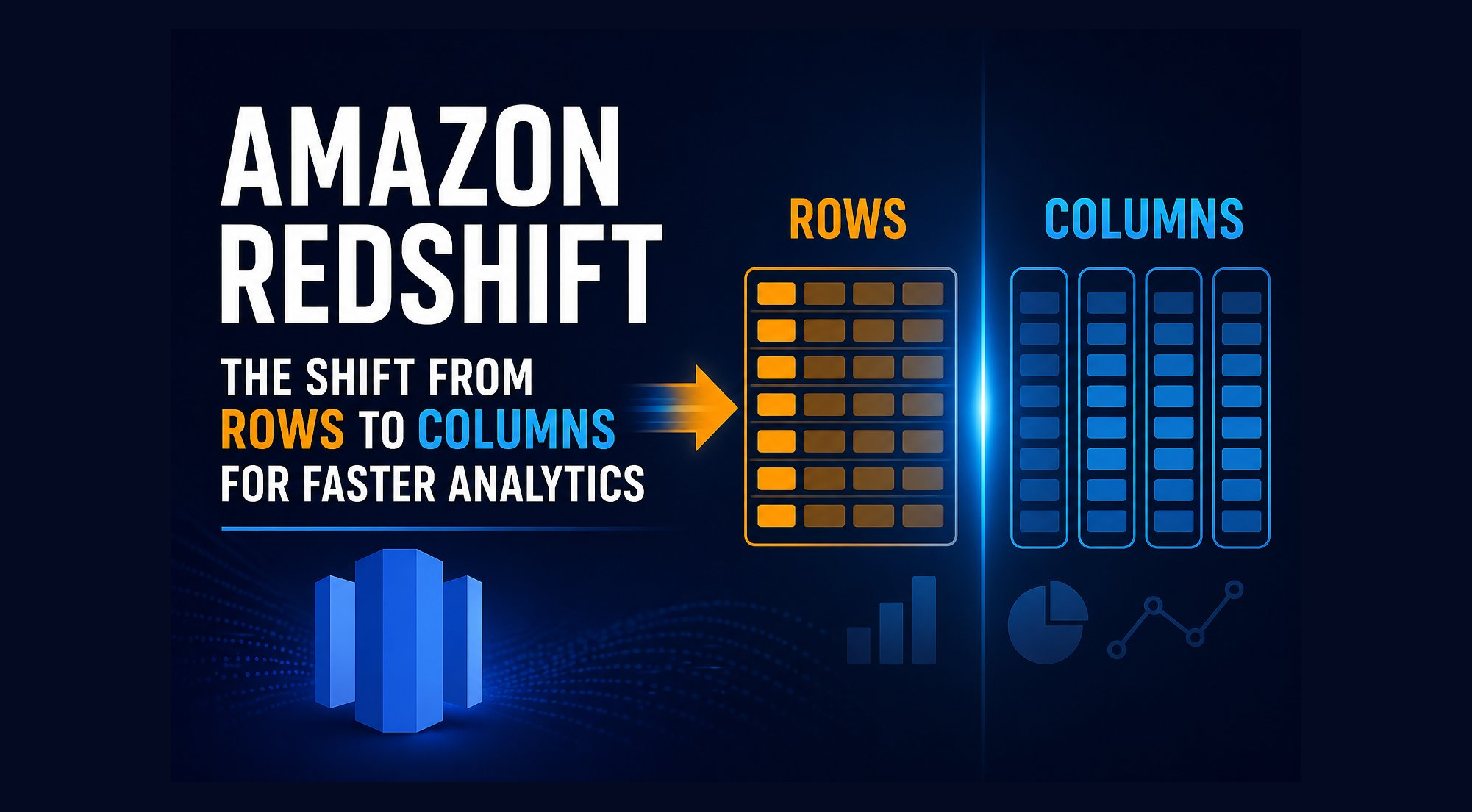
- Row-based storage
- Data of each row is stored together
- Optimized for:
- Fast inserts/updates
- Transactional queries (e.g., order lookup)
- Example use case:
→ Online store transactions
Limitation:
- Inefficient for analytics because column values are scattered on disk
2. OLAP Systems (Amazon Redshift)
- Columnar storage
- Data of each column is stored together
- Optimized for:
- Aggregations (SUM, AVG, MAX)
- Analytical queries
- Example:
- Total sales
- Average price
- Max discount
Result:
- Much faster analytics performance
Why Redshift Exists
Traditional databases are:
- Good for transactions
- Poor for analytics
Redshift solves this by:
Shifting data storage from rows → columns for efficient analytics
How Redshift Works (Conceptually)
- Stores data in columns instead of rows
- Groups similar data together on disk
- Enables:
- Faster scanning
- Efficient aggregations
- Better compression
Key Characteristics
- Columnar data storage
- SQL-based querying
- Fully managed by AWS
- Scales to petabyte-level data
- Requires provisioning (not purely serverless in classic form)
One Liner
- OLTP (RDS) → Reading a full row (like a record card)
- OLAP (Redshift) → Reading only specific columns (like scanning one field across all records)
Final Takeaway
Amazon Redshift = Analytics engine optimized for column-based processing at massive scale
Whenever you think:
- Data warehouse
- Columnar storage
- Large-scale analytics
Think about Amazon Redshift